




SAHA UYGULAMA MÜHENDİSİ
Günümüzde dijitalleşmenin hızla yaygınlaşmasıyla birlikte, ses ve iletişim teknolojilerinde de önemli gelişmeler yaşanmaktadır. Ses sinyalleri dijitalleştirilerek, ileri sinyal işleme algoritmalarıyla analiz edilebilmektedir. Konuşma sentezi gibi gelişmiş uygulamalar mümkün hale gelmekte ve insan-makine etkileşimi yeni boyutlar kazanmaktadır. Bu etkileşimlerden biri de ses tanıma algoritmaları ile gerçekleşir. Ses tanıma algoritmaları, ses verilerinin dijital olarak işlenmesi ve analiz edilmesi yoluyla konuşma ve ses içeriklerini tanımayı amaçlayan yapay zeka teknikleridir. Bu algoritmalar, ses verilerinden belirli özellikleri çıkararak sınıflandırma ve tanıma işlemleri gerçekleştirir. İlk ses tanıma sistemleri kelimelere değil sayılara odaklanmıştı. Bell Laboratuvarları 1952 yılında tek bir sesin yüksek sesle konuştuğu rakamları tanıyabilen “Audrey” sistemini tasarladı. On yıl sonra IBM, İngilizce 16 kelimeyi anlayan ve yanıtlayan “Shoebox “ı tanıttı. Dünya genelinde diğer uluslar da ses ve konuşmaları tanıyabilen donanımlar geliştirdi. Ve 60’ların sonunda, teknoloji dört sesli ve dokuz sessiz harfli kelimeleri destekleyebiliyordu. Ses tanıma 1960’lar itibariyle birçok anlamlı ilerleme kaydetti. Bunun başlıca nedeni ABD Savunma Bakanlığı ve DARPA’ydı. Yürüttükleri Konuşma Anlama Araştırması (SUR) programı, konuşma tanıma tarihinde türünün en büyüklerinden biriydi. Carnegie Mellon’un “Harpy” konuşma sistemi bu programdan çıktı ve üç yaşındaki bir çocuğun kelime dağarcığına eşit olan 1.000’den fazla kelimeyi anlayabiliyordu. 2000’li yıllara girdiğimizde Google, Google Voice Search uygulamasını piyasaya sürene kadar ses tanıma pek fazla gelişim sağlayamamıştı. Ancak milyonlarca insanın kullanımına sunulan bu uygulama ile kullanıcı aramalarından elde edilen kelime sayısı 230 milyarı geçiyordu. Günümüzde Google’ın ses tanıma uygulamasının yanı sıra Siri, Alexa gibi farklı modeller piyasada bulunmakta ve %93-95 gibi yüksek doğruluk oranlarıyla birbirleriyle yarışmaktadırlar.
Ses Tanıma Algoritmalarının Çalışma Prensibi
İnsanlar arasındaki en temel iletişim sesli iletişimdir. Dolayısıyla sesli iletişimin hangi aşamalardan geçtiğini bilmek dijital olarak yorumlamamıza yardımcı olacaktır. Şekil 1’de konuşmacı ve dinleyici arasındaki sesli iletişim modeli verilmiştir.
Şekil 1
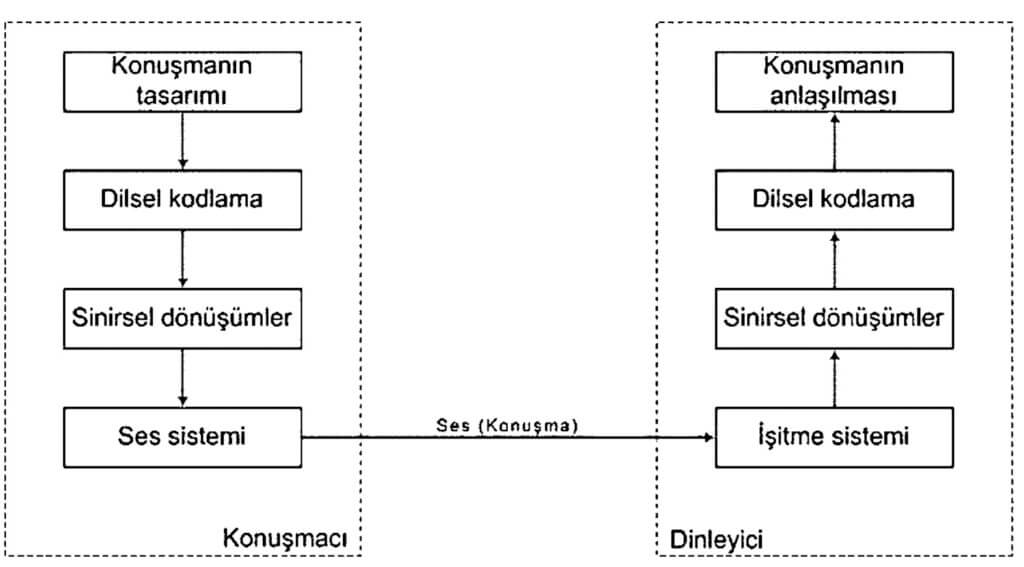
Şekil 1’deki modelde sesli iletişimin gerçekleşebilmesi için konuşmacının ilk önce vermek istediği mesajı düşünmesi ve bir dizi dilsel ve sinirsel süreçten geçirdikten sonra ses sistemine iletmesi gerekiyor. Bu aşamadan sonra artık sesi tanımanın ilk aşaması olan işitme ardından işitilen verinin benzer şekilde bir dizi dilsel ve sinirsel işlemden sonra anlama dönüşmesi bekleniyor. Artık ses tanımayı dijital olarak yorumlayabilmek için tek yapmamız gereken yol haritasını kullanarak bir model oluşturmak. Şekil 2’de oluşturulan dijital model gösterilmektedir.
Şekil 2
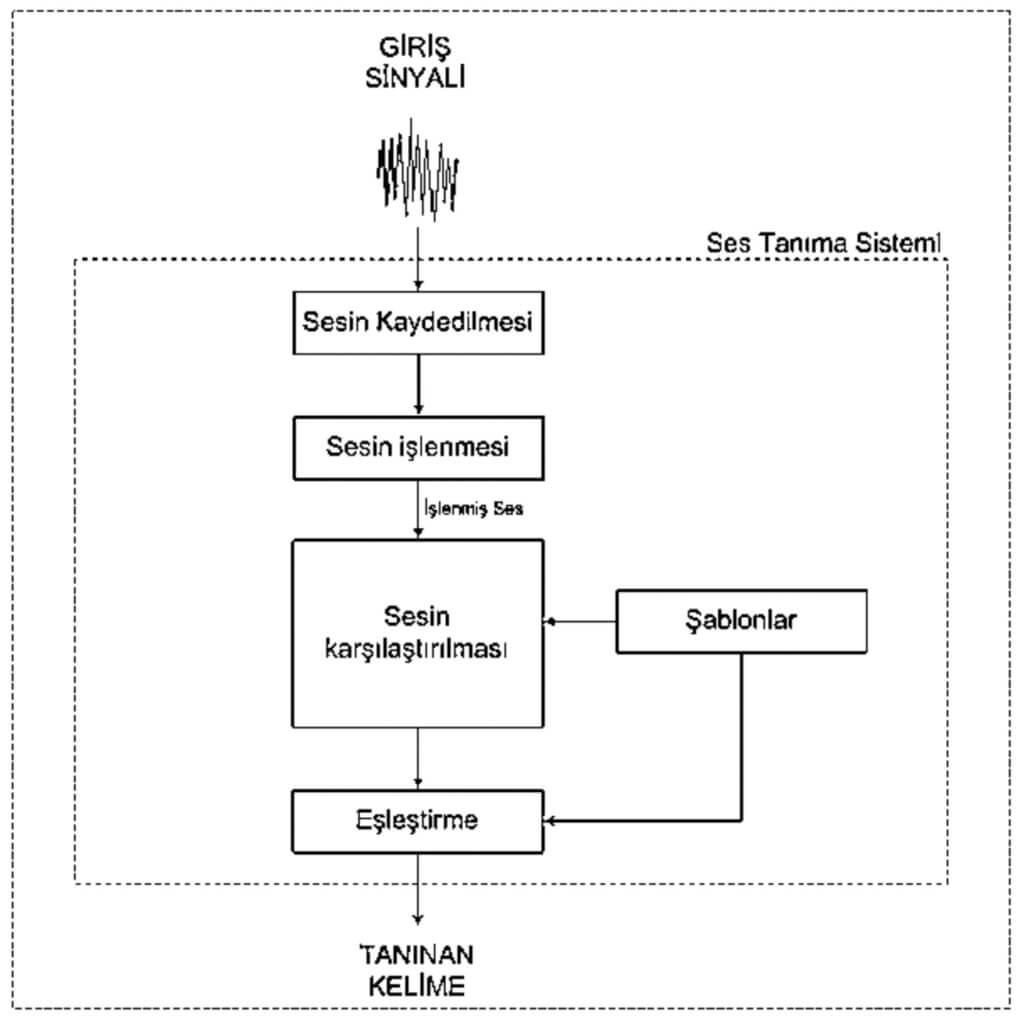
Şekil 2’de aslında şekil 1’deki modelle aynı sürecin yürütüldüğü görülüyor. Buradaki en büyük fark insaninsan arasındaki iletişimi artık insan-makine arasında yaparak kendi isteklerimize göre gidişatı kontrol edebiliyor, yorumlayabiliyor olmamızdır. Bugün geliştirmekte olduğumuz ve geleceğin yaygın teknolojisi olabilecek yapay zeka robotları şuan ağırlıklı olarak insanlarla sesli iletişim kurmak için tasarlanmaktalar. Hayatımızın bir parçası olacak insansı robotlar birbirleriyle iletişimlerini bu teknoloji ile aynı insanlarda da olduğu gibi sesli olarak gerçekleştirebilir. Böylece makine-makine iletişiminin en doğal hali sağlanmış olur.
Milyonlarca insanın kullanımına sunulan bu uygulama ile
kullanıcı aramalarından elde edilen kelime sayısı 230 milyarı geçiyordu.
Ses Tanıma Teknolojilerinin Güvenlik Riskleri ve Çözüm Önerileri
Ses tanıma teknolojilerinin yaygınlaşması bazı güvenlik risklerini de beraberinde getirmektedir. Ses verileri kişisel veri niteliğinde olup, üçüncü şahısların izinsiz erişimine açık hale gelebilmektedir. Bulut ortamlarda işlenen verilerin gizliliği ve bütünlüğü konusunda şüpheler bulunmaktadır. Ayrıca ses tanıma algoritmalarının doğruluk oranlarındaki eksiklikler, yanlış tanımalara ve bunların olası sonuçlarına yol açabilmektedir. Kullanıcıların veri gizliliği haklarının korunması ve algoritmaların şeffaf denetimi, ses tanıma teknolojilerinin güvenilir bir şekilde yaygınlaşmasını sağlayacak önemli unsurlardır.

Türüne Göre Ses Tanıma Algoritmaları
Günümüzde ses tanıma algoritmaları genel olarak ikiye ayrılır:
Online Ses Tanıma:
• İnternet bağlantısı gerektirir.
• Ses verileri bulut ortamında işlenir.
• Daha yüksek doğruluk oranı sağlar.
• Gecikme süresi daha uzundur.
Offline Ses Tanıma:
• İnternet bağlantısı gerekmez.
• Cihazın kendi kaynaklarıyla işlem yapar.
• Daha düşük doğruluk oranıdır.
• Gecikme süresi online tanıma kadar uzun değildir.
Genel olarak online yöntemler daha güçlü sistemlere sahipken, offline yöntemler daha hafif ve gerçek zamanlı çalışır. Uygulamaya göre her iki yöntemden de faydalanılabilir. Donanım özellikleri de tercihi etkiler. Uygulama alanları ve karmaşıklıklarına göre farklı mimaride ses tanıma algoritmaları geliştirilmiştir. Bunlar,
Sesin Sürekliliğine Göre
Ayrık Konuşma: Kullanıcıdan kelimeleri arasına kısa boşluklar ekleyerek konuşması beklenir.
Sürekli Konuşma: Konuşmacının doğal haliyle konuşması beklenir. Bununla birlikte “hmm, mm” gibi ek sesler sistemi engellemez.
Konuşmacıya Bağımlılığına Göre
Kişiye Bağımlı: Ses tanıma gerçekleşebilmesi için kullanıcının sistemde kayıtlı bir ses şablonunun bulunması gerekir.
Kişiden Bağımsız: Bu tip bir ses tanıma sisteminde herhangi bir kullanıcıya bağlı olmaksızın kullanıcının tanınmasına imkan verir
Ses Tanıma Sisteminde Temel Alınan Birime Göre
Sözcük Tabanlı: Bu tip bir ses tanıma sisteminde, tanıma için gerekli en küçük temel birim kelimedir. Sistem gereksinimleri diğer sistemlere daha fazladır.
Fonem Tabanlı: Fonemler, küçük olduğundan şablon oluşturması çak daha kolaydır. Daha az sistem gereksinimine ihtiyaç duyarlar ve bağlantılı olarak üç başlıkta sıralanabilirler. Ses tanıma işlemlerini pratik olarak gerçekleştirebilmek için dijital çevrim ve bir dizi işlemden daha fazlası gerekmektedir. Analog bir ses sinyalinin algılama işlemini mikrofon yapabilir ancak algılanan sinyalin genliği önem arz etmektedir. Bu sebeple ses tanıma yapılacak sistemin mikrofonun çıkış katındaki ses sinyali bir amplifikatör aracılığıyla yükseltilmelidir. Dijital çevrimi yapacak olan ADC modülü yeterli hassasiyete ve hıza sahip olmalıdır. Ses tanıma sistemine göre değişmekle beraber kompleks algoritmalar için ses tanımaya özel işlem modülünün bulunması gerekir. Her ses tanıma sisteminin kendine özgü şablonu
bulunur. Şablonlar ses tanıma yapılacak kelime ya da foneme göre çok sayıda ses örneğiyle oluşturulurlar. Şablonun kalitesini aynı zamanda oluşturulduğu örnek sayısı belirler. Örneğin sadece 1 komut için ortalama her kişi 10 tekrar yapacak şekilde 200 kişinin, dolayısıyla 2000 örneğin kullanıldığı şablonlar bulunmaktadır. Dolayısıyla bu örnekleri için halihazırda çalışmalar gerçekleştiren 3.parti yazılımlar başvurmakta büyük fayda vardır. Kompleks ses tanıma algoritmaları ve şablonlar kullanılmak
için DSP işlemlerine ihtiyaç duyar. Bazı uygulamalarda ses tanıma gerçekleştikten sonra dönüt olarak yine ses çalınması istenir. Sesi tekrar çalmak için PWM ya da DAC modüllerine ihtiyaç duyulur. Bununla birlikte yeterli ses seviyesine erişebilmek için çıkışta bir amplifikatör kullanılmalıdır. Yukarıdaki maddelerin her biri için ayrı çözümler üretilirse ses tanıma işlemleri hem zor hem de maliyetli olacaktır. Bu sebeple bu çözümlerin hepsini bulunduran ürün ya da sistemlere yönelmek en doğrusu olacaktır. Bu ürünlerden biri de offline ses tanıma işlemlerini gerçekleştirebilen Nuvoton ses mikrodenetleyicileridir.
Özdisan Elektronik, Nuvoton’un Avrupa ve Türkiye’deki en büyük distribütörü
olarak geniş ürün yelpazesini müşterilerine çözüm olarak sunmaktadır.
Nuvoton Ekosisteminde Ses Tanıma

Nuvoton Teknoloji, Taiwan menşeili bir yarı iletken üreticisidir. Mikrodenetleyici, mikroişlemci, akıllı ev, bulut güvenliği, pil izleme, bileşen, görsel algılama ve IoT ile güvenlik entegrelerinin üretilmesine ve geliştirilmesine odaklanmaktadır. Özdisan Elektronik, Nuvoton’un Avrupa ve Türkiye’deki en büyük distribütörü olarak geniş ürün yelpazesini müşterilerine çözüm olarak sunmaktadır. Bugün kullandığımız bilgisayar, teyp, telefon vb. cihazların içinde Nuvoton ses entegrelerine rastlamaktayız. Ses sinyalinin üretimi, işlenmesi ve çalınmasına kadar tüm aşamalarda Nuvoton ürünleri kullanılabilir. Nuvoton aynı zamanda ARM tabanlı mikrodenetleyici üreticisi olduğundan bazı ses entegreleri aynı zamanda bir mikrodenetleyici olarak kullanılabilir. Bu ürün ailelerinden biri de ses tanıma işlemlerini gerçekleştirebilen ISD ürün grubudur. ISD serisi ARM tabanlı, 32 Bit, M0 ve M4 mimarilerinde tasarlanmış ses işlemeye tekil çözüm sunabilen özel mikrodenetleyicilerdir. İçerisinde barındırdığı dijital mikrofon amplifikatörleri ve ses çıkış katı amplifikatörleri ile ek bir komponente ihtiyaç duymadan ses kayıt, çalma ve işleme süreçlerini tek başına yapabilir. Bu yazıda ses tanıma işlemlerine odaklanıldığından, baz alınacak Nuvoton ürünü ISD94124C modelidir. ISD94 serisi M4 tabanlı özelleştirilmiş bir ses mikrodenetleyicisidir. İçerisinde bulundurduğu ses tanıma işlemlerini gerçekleştirdiği özel modül ile en optimum ses tanıma performansını vermeye çalışır. DSP işlemlerini de gerçekleştirebilen bu ürün ses tanıma için gerekli kompleks hesapları rahatlıkla yapabilir. Şekil 4’te LQFP64 kılıflı ISD94124C entegresi gösterilmiştir.
Nuvoton ile Ses Tanıma İşlemlerine Genel Bakış
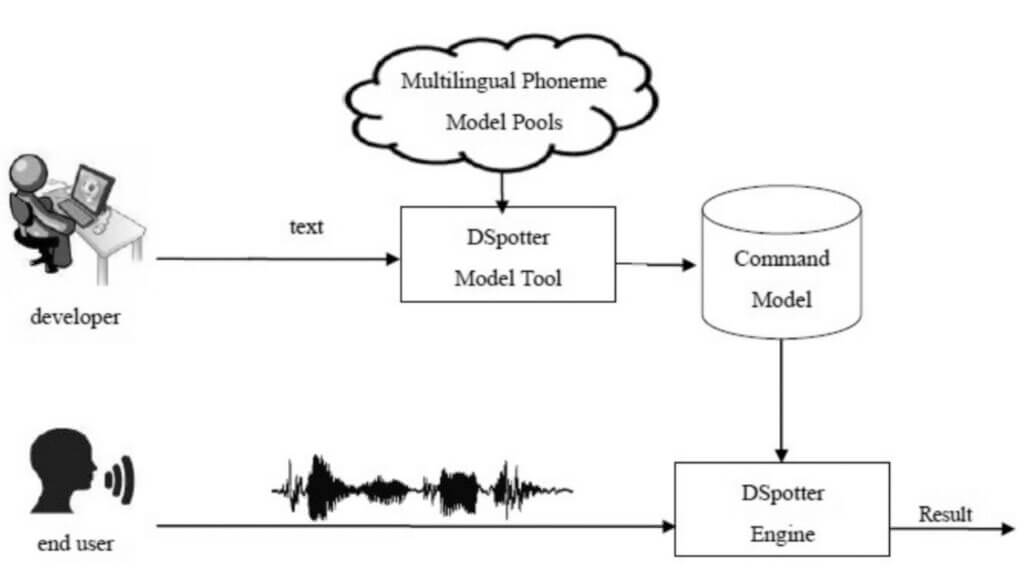
Önceki konularda ses tanıma için gerekli sistemin dışında şablonlardan bahsetmiştim. Nuvoton firması şablonları 3. parti bir yazılım olan Cyberon platformundan sağlamaktadır. Cyberon Taiwan merkezli bir gömülü konuşma çözüm sağlayıcısıdır. 30’u aşkın farklı dilde fonem tabanlı ses tanıma algoritmalarına sahiptirler. Cyberon sözcük tabanlı ses tanıma algoritmaları CSpotter ve DSpotter adında iki farklı nöral model ile işler. DSpotter: Düşük güçlü, sürekli uyanık kalabilen, gürültülü ortamlara bağışıklı, çevrimdışı bir sinir ağı modelidir. DSpotter modelinin en önemli avantajı sadece metin girişiyle ses tanıma işlemlerini yapabiliyor olmasıdır. Ek olarak ses kaydına ihtiyaç duymaz kişiden bağımsızdır. CSpotter: Sürekli uyanık kalabilen, çevrimdışı bir sinir ağı modelidir. Daha düşük boyutlu komut paketlerine sahiptir. Önceden konuşma verilerini toplamaya ihtiyaç duymadan ses kaydı ile tanıma işlemleri gerçekleştirebilir. İki model arasında en kapsamlısı DSpotter modelidir. Dolayısıyla bu yazıda DSpotter üzerinden ilerlemeye devam edeceğim.
Şekil 5’te DSpotter modelinin işlem diagramı verilmiştir.

Şekil 5
DSpotter modeli 32-bit platformlarda DSP32 algoritmasını kullanmaktadır. Şekil 6’da DSpotter modelinin ortalama sistem gereksinimleri verilmiştir.
Şekil 6
DSpotter kullanırken istenilen komutlar için sadece metin yazmak yeterli olduğundan; Cyberon platformu uygulama arayüzünün Türkçe dil için yapılmış örneği şekil 7’de gösterilmiştir.
Şekil 7
Uygulama ile oluşturulan örnek kayıt dizininde “.bin” formatında oluşur. Kullanıcının tek yapması gereken halihazırda ses tanıma için kullanılan Nuvoton örnek kodlarını oluşturulan Cyberon projesiyle birleştirmektir. Nuvoton miktodenetleyicilerinde derleyici olarak kullanılan Keil platformuna ait kod görseli şekil 8’de gösterilmiştir.
Şekil 8
ISD94124C entegresi artık bu işlemlerden sonra istemiş olduğumuz komutları tanıyacak ve tanıma sonrası gerek ses çalma, gerekse diğer kontrol işlemlerini yapabilecektir. Yukarıdaki satırlarda sizlere ses tanıma sistemlerinin işleyişini göstermek ve Nuvoton’un komponentlerinden yararlanarak bu sürecin ne kadar kolay olabileceğini göstermek istedim. Türkiye’de yakın gelecekte yaygınlaşması kaçınılmaz ses tanıma teknolojisinin Özdisan Elektronik öncülüğünde olacağına şüphem yok. Günlük hayatımızın bir parçası olacak bu teknolojinin imkanlarından yararlanmanın, yenilikleri takip etmenin hepimizin faydasına olacağını düşünüyorum. Teknoloji çağında hep bir adım önde kalmak dileğiyle!