



Today, with the rapid spread of digitalization, there have been significant developments in audio and communication technologies. Audio signals can be digitized and analyzed with advanced signal processing algorithms. Advanced applications such as speech synthesis become possible and human-machine interaction gains new dimensions. Voice recognition algorithms are artificial intelligence techniques that aim to recognize speech and audio content by digitally processing and analyzing audio
data. These algorithms perform classification and recognition by extracting certain features from audio data. The first speech recognition systems were focused on numbers, not words. In 1952, Bell Laboratories designed the “Audrey” system which could recognize a single voice speaking digits aloud. Ten years later, IBM introduced “Shoebox” which understood and responded to 16 words in English. Across the globe other nations developed hardware that could recognize sound and speech. And by the end of the ‘60s, the technology could support words with four vowels and nine consonants. Speech recognition made several meaningful advancements in this decade. This was mostly due to the US
Department of Defense and DARPA. The Speech Understanding Research (SUR) program they ran was one of the largest of its kind in the history of speech recognition. Carnegie Mellon’s “Harpy’ speech system came from this program and was capable of understanding over 1,000 words which is about the same as a three-year-old’s vocabulary. When we entered the 2000s, voice recognition had not made much progress until Google launched Google Voice Search. However, with this application available to millions of people, the number of words obtained from user searches exceeded 230 billion. Today, in addition to Google’s voice recognition application, different models such as Siri and Alexa are available on the market and compete with each other with high accuracy rates of 93-95%.
Working Principle of Voice Recognition Algorithms
The most basic communication between people is voice communication. Therefore, knowing the stages that voice communication goes through will help us interpret it digitally. Figure 1 shows the voice communication model between speaker and listener.
Figure 1
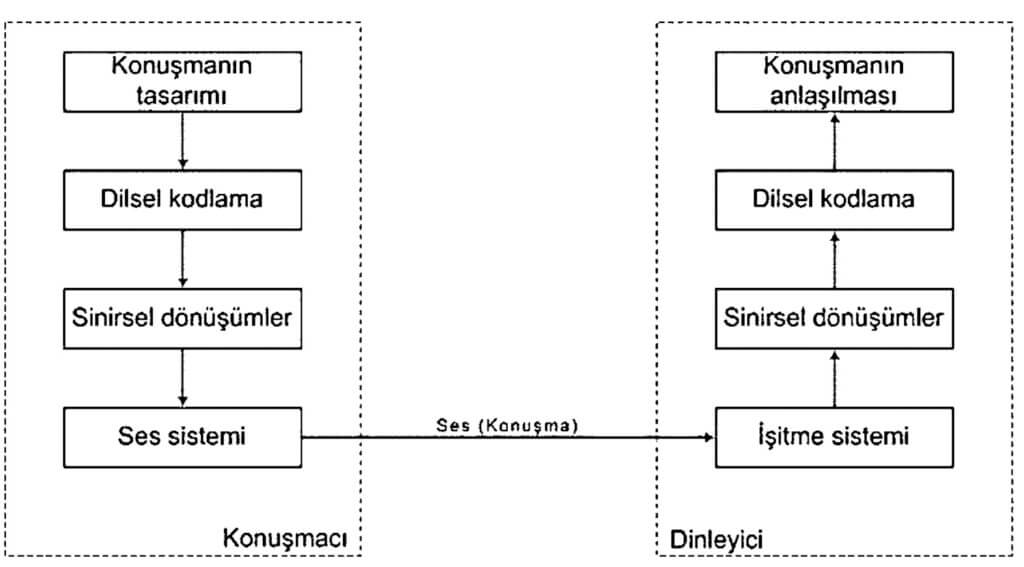
In the model in Figure 1, in order for voice communication to take place, speakers must first think about the message they want to convey and then transmit it to the sound system after going through a series of linguistic and neural processes. After this stage, hearing, which is the first stage of voice recognition, is expected to be followed by a similar series of linguistic and neural processes to transform the heard data into meaning. Now all we need to do to digitally interpret voice recognition is to create a model using the roadmap. Figure 2 shows the digital model created.
Figure 2
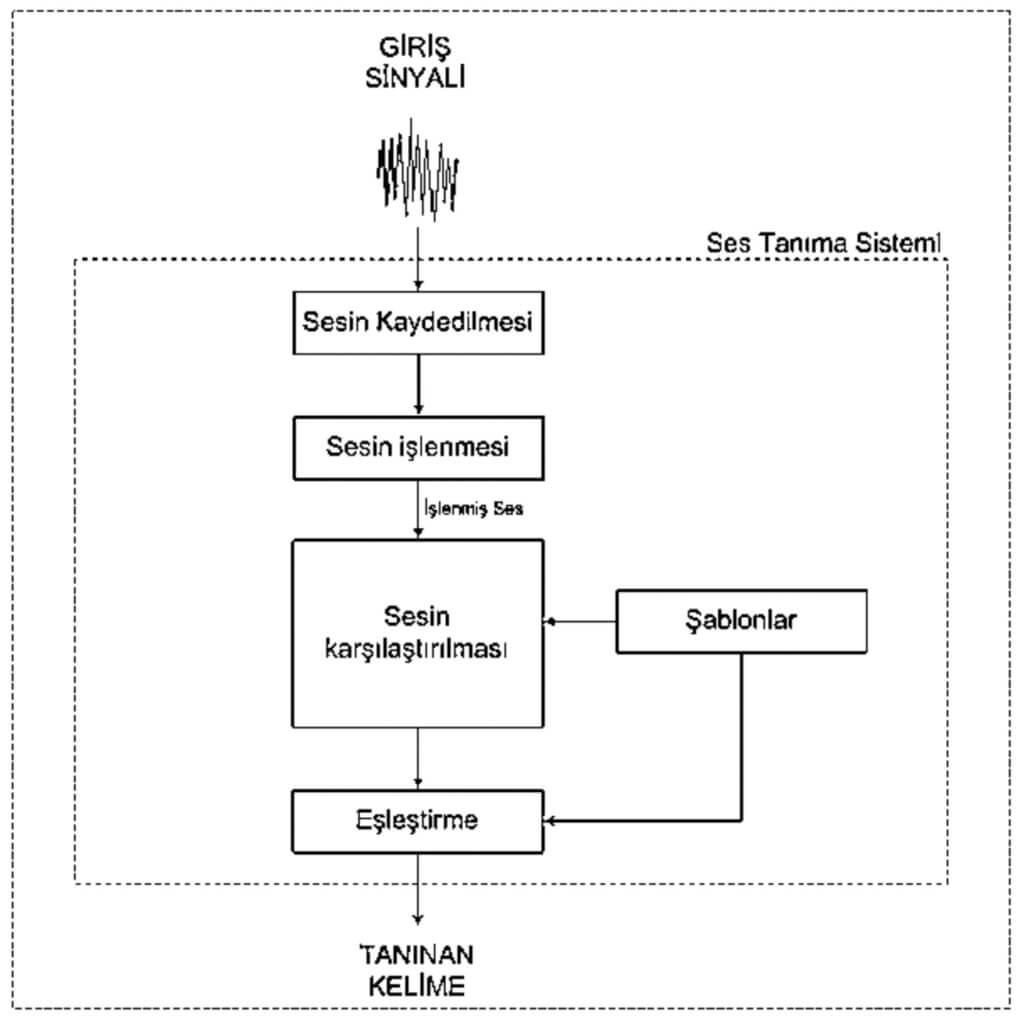
Figure 2 actually shows the same process as the model in Figure 1. The biggest difference here is that we are now able to control and interpret the course of events according to our own wishes by making the communication between human and machine. Artificial intelligence robots, which we are developing today and which may be the common technology of the future, are now mainly designed to communicate with humans by voice. Humanoid robots, which will be a part of our lives, can communicate with each other with this technology, just like humans. Thus, the most natural form of machine-to-machine communication is provided.
However, with this application available to millions of people, the number of words obtained from user searches exceeded 230 billion.
Security Risks and Solutions For Voice Recognition Technologies
The widespread use of voice recognition technologies brings with it some security risks. Voice data is
personal data and may be open to unauthorized access by third parties. There are doubts about the
confidentiality and integrity of data processed in cloud environments. In addition, the lack of accuracy of voice recognition algorithms can lead to false recognitions and their possible consequences. Protection of users’ data privacy rights and transparent auditing of algorithms are important factors that will ensure the reliable deployment of voice recognition technologies.

Voice Recognition Algorithms by Type
Today, voice recognition algorithms are generally
divided into two types:
Online Voice Recognition:
• Requires an internet connection.
• Voice data is processed in the cloud environment.
• Provides a higher accuracy rate.
• Latency is longer.
Offline Voice Recognition:
• No internet connection required.
• Processes with the device’s own resources.
• Lower accuracy rate.
• Latency is not as long as online recognition.
In general, online methods have more powerful systems, while offline methods are lighter and work in real time. Depending on the application, both methods can be used. Hardware features also affect the choice.
According to Sound Continuity
Discrete Speech: The user is expected to speak with short spaces between words.
Continuous Speech: The speaker is expected to speak naturally. However, additional sounds such as “hmm, mm” do not block the system.
According to Speaker Dependency
Person Dependent: For voice recognition to take place, the user must have a voice template stored in the system. Person Independent: This type of voice recognition system allows the user to be recognized without depending on any user.
According to the Unit Based on the Voice Recognition System
Word-based: In this type of voice recognition system, the smallest basic unit required for recognition is the word. The system requirements are higher than other systems.
Phoneme-based: In this type of voice recognition system, the smallest basic unit required for recognition is the phoneme. Since phonemes are small, they are much easier to create templates and therefore require less system requirements. The phoneme-based systems can be listed under 3 interconnected headings. An analog audio signal can be detected by a microphone, but the amplitude of the detected signal is important. For this reason, the sound signal at the output stage of the microphone must be amplified through an amplifier. The ADC module that will perform the digital conversion must have sufficient sensitivity and speed. Depending on the voice recognition system, a voice recognition specific processing module is required for complex algorithms. Each voice recognition system has its own unique template. Templates are created with a large number of audio samples according to the word or phoneme to be recognized. The quality of the template is also determined by the number of samples used. For example, for just one command, there are templates where 200 people, and thus 2000 samples, are used, with each person doing 10 repetitions on average. Therefore, it is useful to consult 3rd party software that is already working on these samples.
Complex voice recognition algorithms and templates require DSP processing to be used. In some
applications, after voice recognition, it is required to play the voice again as feedback. PWM or DAC
modules are needed to play the sound again. However, an amplifier must be used at the output to achieve sufficient volume. If each of the above items is realized with separate solutions, voice recognition will be both difficult and costly. For this reason, it would be best to turn to products or systems that contain all of these solutions.
As the largest distributor of Nuvoton in Europe and Türkiye, Özdisan Electronic offers
a wide range of products as solutions to its customers.
Voice Recognition in the Nuvoton Ecosystem

Nuvoton Technology Corporation is a semiconductor manufacturer based in Taiwan. It focuses on the production and development of microcontroller, microprocessor, smart home, cloud security, battery
monitoring, component, visual sensing and IoT and security integrations. As the largest distributor of Nuvoton in Europe and Türkiye, Özdisan Electronic offers a wide range of products as solutions to its customers. Today, we find Nuvoton audio integrators in the devices we use such as computers, tape recorders, telephones, etc. Nuvoton products can be used in all stages of audio signal generation, processing and playback. Since Nuvoton is also an ARM-based microcontroller manufacturer, some audio integrators can also be used as a microcontroller. One of these product families is the ISD product group that can perform voice recognition operations. The ISD series
are ARM-based, 32-bit, M0 and M4 architectures designed to provide a single solution for audio
processing. With its digital microphone amplifiers and audio output stage amplifiers, it can perform audio recording, playback and processing without the need for additional components. Since this article focuses on voice recognition, the Nuvoton product to be used as a base is the ISD94124C. The ISD94 series is an M4-based customized audio microcontroller. It tries to give the most optimum voice recognition performance with the special module that performs voice recognition operations. This
product, which can also perform DSP operations, can easily perform the complex calculations required for voice recognition. Figure 4 shows the ISD94124C with LQFP64 package.
Figure 4
The ISD94124C can perform voice recognition with 32 language support. It performs voice recognition offline without connecting to the internet, so the operations are very fast. However, it can recognize up to 100 commands.
Nuvoton Voice Recognition Overview
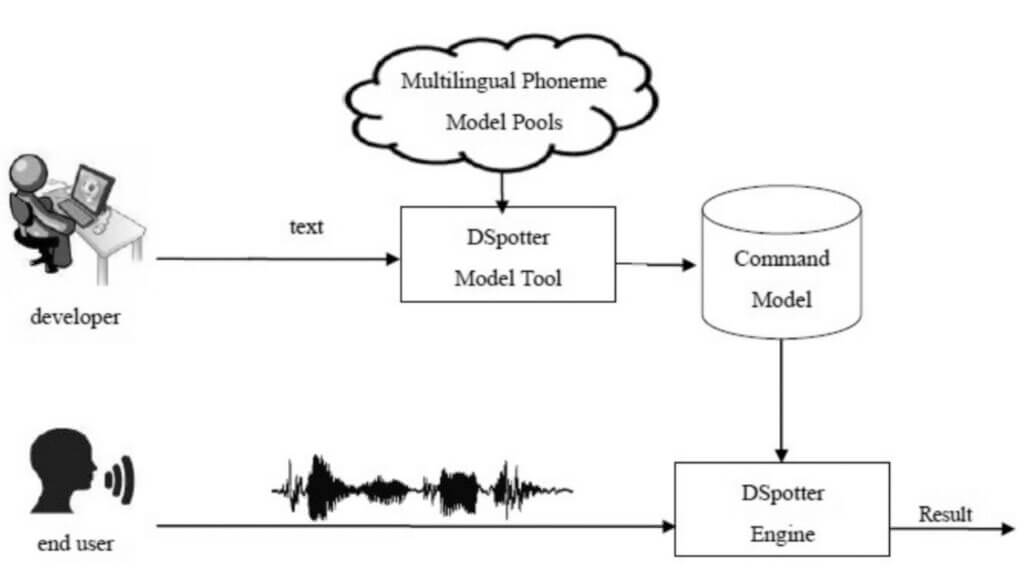
In previous topics I have mentioned the templates for voice recognition in addition to the system. Nuvoton provides the templates from the Cyberon platform, which is a 3rd party software. Cyberon is a Taiwan-based embedded speech solution provider. They have phoneme-based voice recognition algorithms in over 30 different languages. Cyberon word-based voice recognition algorithms work with two different neural models, CSpotter and DSpotter. DSpotter : It is a low-power, continuously awake, immune to noisy environments, offline neural network model. The most important advantage of the DSpotter model is that it can perform voice recognition with only text input. In addition, it does not need audio recording and is independent of the person. CSpotter : It is an offline neural network model that can stay awake all the time. It has lower size command packets. It can perform recognition with voice recordings without the need to collect speech data in advance. DSpotter is the more comprehensive of the two
models. Therefore, I will continue to focus on DSpotter in this paper.
Figure 5 shows the process diagram of the DSpotter model.

Figure 5
The DSpotter model uses the DSP32 algorithm on 32-bit platforms. Figure 6 shows the average system requirements of the DSpotter model.
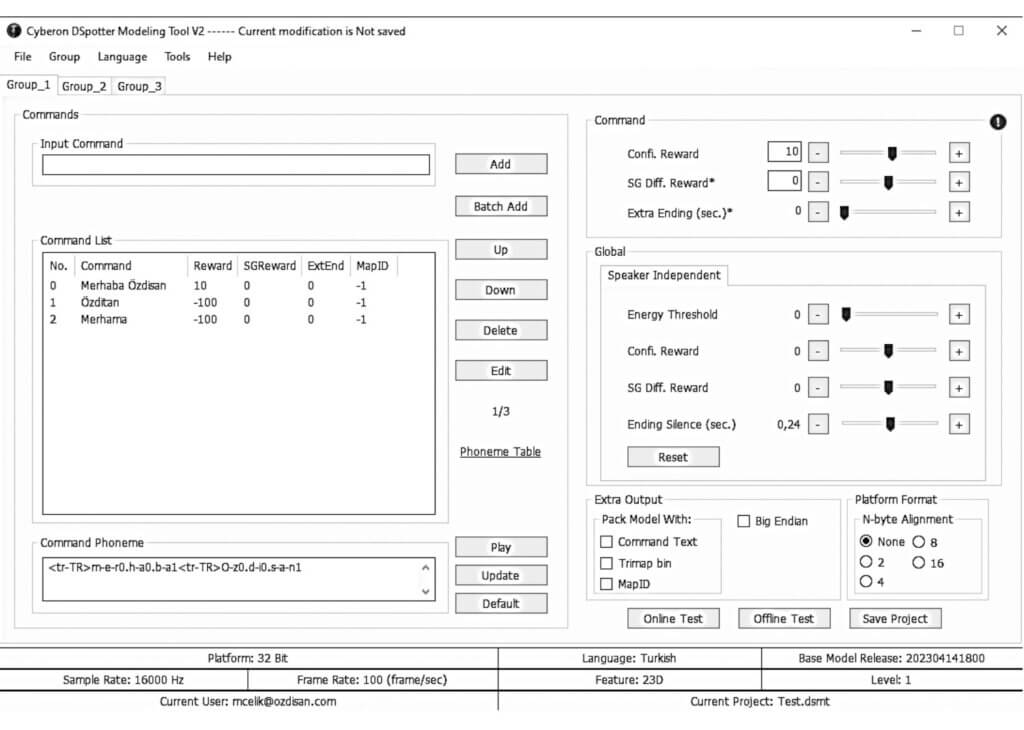
Figure 6
Since it is sufficient to write only text for the desired commands when using DSpotter, an example of the Cyberon platform application interface for the Turkish language is shown in Figure 7.
Figure 7
The sample generated with the application is created in “.bin” format in the registry directory. All the user needs to do is to combine the Nuvoton sample code already used for voice recognition with the Cyberon project. The code visualization of the Keil platform used as a compiler in Nuvoton microcontrollers is shown in Figure 8.
Figure 8
The ISD94124C integration will now recognize the commands we want after these processes and will be able to perform both audio playback and other control operations after recognition. In the lines above, I wanted to show you how voice recognition systems work
and how easy this process can be by making use of Nuvoton’s components. I have no doubt that the voice recognition technology that will inevitably become widespread in Türkiye in the near future will be led by Özdisan Electronic. I think it will be beneficial for all of us to take advantage of the possibilities of this technology, which will be a part of our daily lives, and to follow the innovations. Hope to stay one step ahead in the age of technology!